原理
采用完全基于 channel+select 的实现方案,不使用其他数据结 构,也不使用 sync 包提供的各种同步结构,比如 Mutex、RWMutex,以及 Cond 等。
线程池的实现主要分为 三个部分:
pool的创建与销毁
pool 中worker(Goroutine)的管理
task 的提交与调度
其中,后两部分是 pool 的“精髓”所在,这两部分的原理我也用一张图表示了出来:
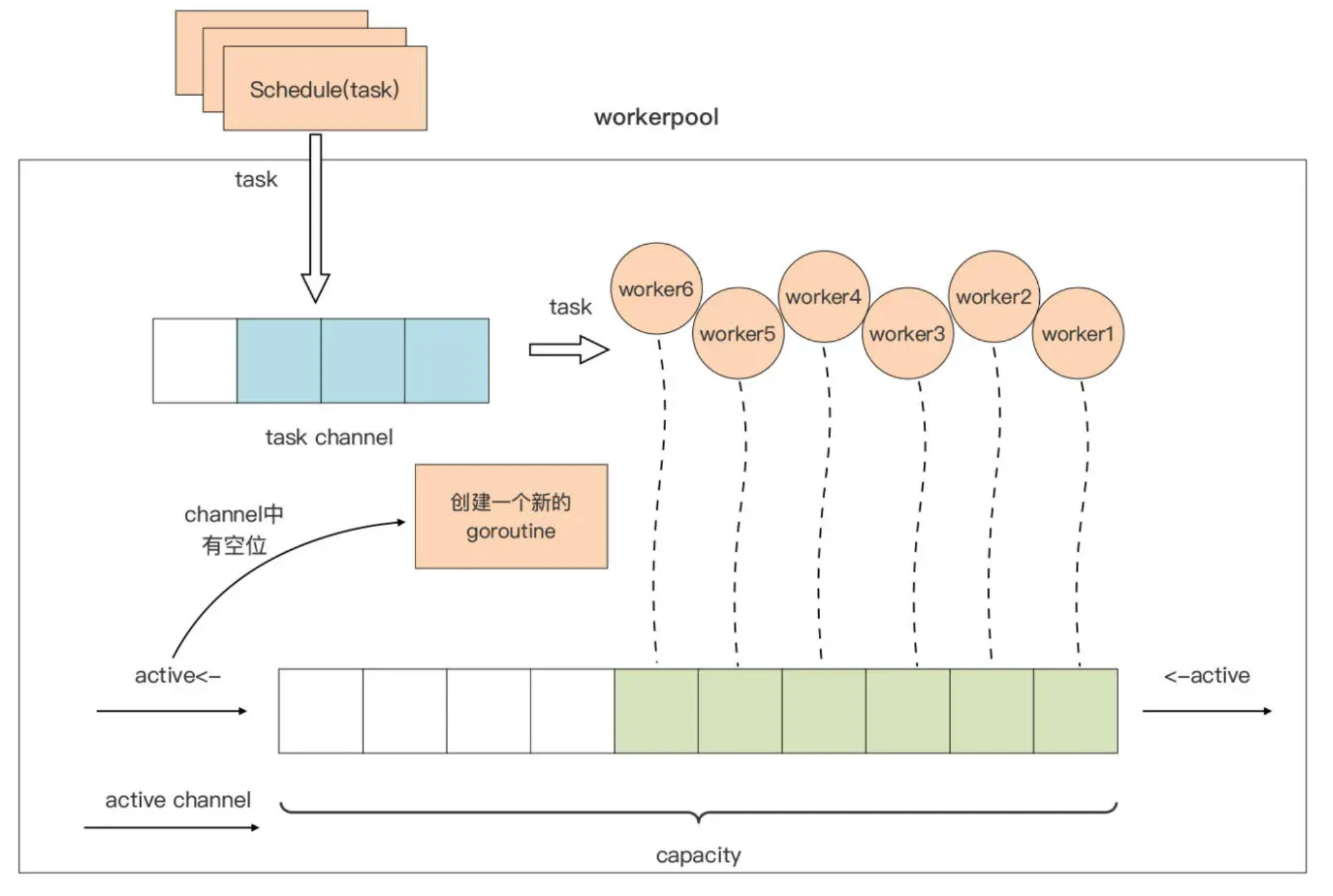
我们先看一下图中 pool 对 worker 的管理。
capacity 是 pool 的一个属性,代表整个 pool 中 worker 的最大容量。我们使用一个带缓 冲的 channel:active,作为 worker 的“计数器”
当 active channel 可写时,我们就创建一个 worker,用于处理用户通过 Schedule 函数 提交的待处理的请求。当 active channel 满了的时候,pool 就会停止 worker 的创建,直 到某个 worker 因故退出,active channel 又空出一个位置时,pool 才会创建新的 worker 填补那个空位。
这张图里,我们把用户要提交给 workerpool 执行的请求抽象为一个 Task。Task 的提交 与调度也很简单:Task 通过 Schedule 函数提交到一个 task channel 中,已经创建的 worker 将从这个 task channel 中读取 task 并执行。
好了!“Talk is cheap,show me the code”!接下来,我们就来写一版代码,来验证一下这里分析的原理是否可行。
线程池的一个最小可行实现
创建一个包,命名为workerpool
定义 Pool 结构体类型,这个类型的实例代表一个workerpool
1 | // Pool is a worker pool. |
workerpool 包对外主要提供三个 API,它们分别是:
workerpool.New: 用于创建一个 pool 类型实例,并将 pool 池的 worker 管理机制运 行起来;
workerpool.Free: 用于销毁一个 pool 池,停掉所有 pool 池中的 worker;
Pool.Schedule: 这是 Pool 类型的一个导出方法,workerpool 包的用户通过该方法向 pool 池提交待执行的任务(Task)。
接下来我们就重点看看这三个 API 的实现。
我们先来看看 workerpool.New 是如何创建一个 pool 实例的:
1 | // New creates a new worker pool with default capacity. |
我们看到,New 函数接受一个参数 capacity 用于指定 workerpool 池的容量,这个参数 用于控制 workerpool 最多只能有 capacity 个 worker,共同处理用户提交的任务请求。 函数开始处有一个对 capacity 参数的“防御性”校验,当用户传入不合理的值时,函数 New 会将它纠正为合理的值。
Pool 类型实例变量 p 完成初始化后,我们创建了一个新的 Goroutine,用于对 workerpool 进行管理,这个 Goroutine 执行的是 Pool 类型的 run 方法:
1 | // run the worker pool. |
run 方法内是一个无限循环,循环体中使用 select 监视 Pool 类型实例的两个 channel: quit 和 active。这种在 for 中使用 select 监视多个 channel 的实现,在 Go 代码中十分 常见,是一种惯用法。
当接收到来自 quit channel 的退出“信号”时,这个 Goroutine 就会结束运行。而当 active channel 可写时,run 方法就会创建一个新的 worker Goroutine。 此外,为了方 便在程序中区分各个 worker 输出的日志,我这里将一个从 1 开始的变量 idx 作为 worker 的编号,并把它以参数的形式传给创建 worker 的方法。
我们再将创建新的 worker goroutine 的职责,封装到一个名为 newWorker 的方法中:
1 | // newWorker creates a new worker. |
我们看到,在创建一个新的 worker goroutine 之前,newWorker 方法会先调用 p.wg.Add 方法将 WaitGroup 的等待计数加一。由于每个 worker 运行于一个独立的Goroutine 中,newWorker 方法通过 go 关键字创建了一个新的 Goroutine 作为 worker。
新 worker 的核心,依然是一个基于 for-select 模式的循环语句,在循环体中,新 worker 通过 select 监视 quit 和 tasks 两个 channel。和前面的 run 方法一样,当接收到来自 quit channel 的退出“信号”时,这个 worker 就会结束运行。tasks channel 中放置的 是用户通过 Schedule 方法提交的请求,新 worker 会从这个 channel 中获取最新的 Task 并运行这个 Task。
Task 是一个对用户提交的请求的抽象,它的本质就是一个函数类型:
1 | // Task is the task to be executed. |
这样,用户通过 Schedule 方法实际上提交的是一个函数类型的实例。
在新 worker 中,为了防止用户提交的 task 抛出 panic,进而导致整个 workerpool 受到 影响,我们在 worker 代码的开始处,使用了 defer+recover 对 panic 进行捕捉,捕捉后 worker 也是要退出的,于是我们还通过<-p.active更新了 worker 计数器。并且一旦 worker goroutine 退出,p.wg.Done 也需要被调用,这样可以减少 WaitGroup 的 Goroutine 等待数量。
我们再来看 workerpool 提供给用户提交请求的导出方法 Schedule:
1 | // Schedule submits a task to the worker pool. |
Schedule 方法的核心逻辑,是将传入的 Task 实例发送到 workerpool 的 tasks channel 中。但考虑到现在 workerpool 已经被销毁的状态,我们这里通过一个 select,检视 quit channel 是否有“信号”可读,如果有,就返回一个哨兵错误 ErrWorkerPoolFreed。如 果没有,一旦 p.tasks 可写,提交的 Task 就会被写入 tasks channel,以供 pool 中的 worker 处理。
这里要注意的是,这里的 Pool 结构体中的 tasks 是一个无缓冲的 channel,如果 pool 中 worker 数量已达上限,而且 worker 都在处理 task 的状态,那么 Schedule 方法就会阻 塞,直到有 worker 变为 idle 状态来读取 tasks channel,schedule 的调用阻塞才会解 除。
我们再来看看如何关闭线程池:
1 | // Free closes the worker pool. |
至此,workerpool 的最小可行实现的主要逻辑都实现完了。我们来验证一下它是否能按照 我们的预期逻辑运行。
1 | func main() { |
这个示例程序创建了一个 capacity 为 5 的 workerpool 实例,并连续向这个 workerpool 提交了 10 个 task,每个 task 的逻辑很简单,只是 Sleep 3 秒后就退出。main 函数在提 交完任务后,调用 workerpool 的 Free 方法销毁 pool,pool 会等待所有 worker 执行完 task 后再退出。
运行结果如下:
1 | worker pool start |
从运行的输出结果来看,workerpool 的最小可行实现的运行逻辑与我们的原理图是一致的。